Workflow Types
Skyhook supports two Argo workflow types:Argo Workflow
Multi-step orchestrationWorkflows with multiple steps, dependencies, and data flow. Best for ETL pipelines, ML training, and processes requiring step coordination.
Argo CronWorkflow
Scheduled orchestrationRecurring multi-step workflows with cron scheduling. Best for periodic data pipelines and processes with coordinated stages.
Argo Workflow
One-time multi-step workflows perfect for ETL pipelines, ML training, and complex data processing. What Skyhook provides:- Template deployment through UI
- Parameter management and execution
- Real-time monitoring with Argo UI integration
- Step-by-step logs and status tracking
Argo CronWorkflow
Scheduled multi-step workflows that combine Argo’s orchestration with cron scheduling. What Skyhook provides:- Common Argo Workflow features + cron scheduling in the UI
- Timezone-aware schedule configuration
- Manual execution outside schedule (“Execute Now” button)
- Parameter support for each execution
Template-Based Architecture
Argo workflows use a template/instance model optimized for reusability. The WorkflowTemplate (reusable definition) is stored in Git and deployed to your cluster. Each execution creates a Workflow instance dynamically at runtime. These instances are ephemeral and cleaned up based on TTL settings. Execution flow:Repository Structure
Your workflow lives in Git with Kustomize-based structure for environment-specific overrides:WorkflowTemplate Example
TheWorkflowTemplate in the base directory defines reusable workflow logic:
Environment-Specific Patches
Each environment can override settings using Kustomize patches: Development (overlays/dev/argo-workflowtemplate-patch.yaml):
overlays/prod/argo-workflowtemplate-patch.yaml):
Workflow Instance Creation
When you execute a workflow from the Skyhook UI:- GitHub Actions workflow (
execute_job.yml) is triggered - Workflow authenticates with your cluster
- Uses
argo submitCLI command to create a Workflow instance - Passes parameters you provided in the execution dialog
- Workflow executes in your cluster
- Template defined once, executed many times with different parameters
- Environment-specific overrides without duplicating workflow logic
- Clean Git history (only templates tracked, not ephemeral instances)
Creating a Workflow
1. Access the Job Creation Form
- Navigate to Jobs in the Skyhook UI
- Click Create New Job
- Select Argo Workflow or Argo CronWorkflow as job type
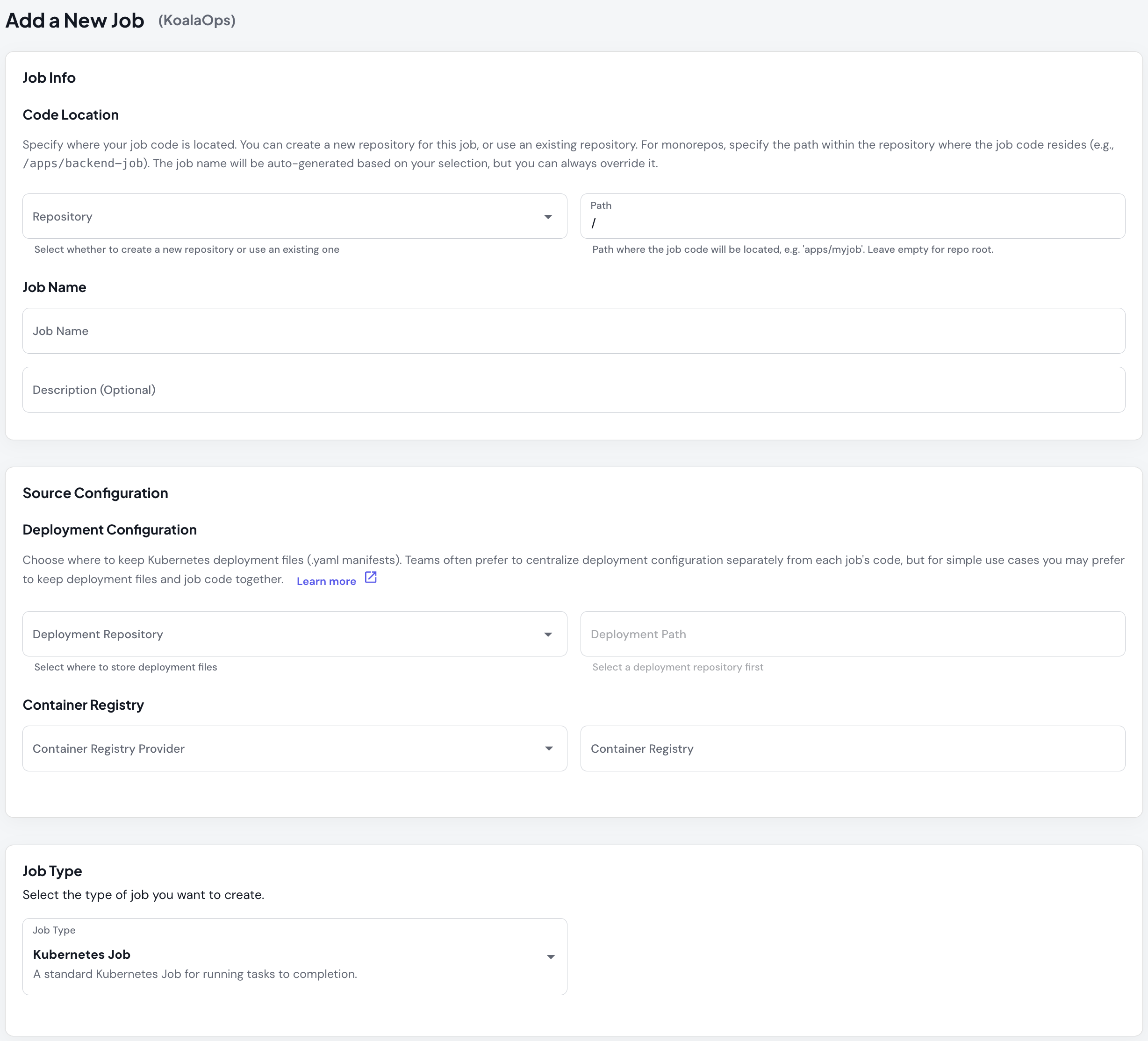
2. Basic Details
Same as Kubernetes Jobs - configure name, description, container registry, and repository.3. Job Type Selection
Choose Argo Workflow (one-time) or Argo CronWorkflow (scheduled). For CronWorkflow, configure:- Cron Schedule - Standard cron expression
- Timezone - IANA timezone for accurate scheduling
- Concurrency Policy - How to handle overlapping runs
4. Add Environments
Configure where your workflow will run (dev, staging, prod).Repository Configuration: Like Kubernetes Jobs, Argo Workflows support multiple jobs in one repository and flexible deployment repository options. See the Kubernetes Jobs documentation for detailed repository configuration options.
5. Configure Parameters (Optional)
After creating the workflow, go to the Settings tab to define parameters under Workflow Parameters: Each parameter has:- Name - Identifier used in your workflow (e.g.,
input-file,batch-size) - Default Value - Used if not overridden at execution time
- Description - Help text displayed to users in the Execute dialog
{{workflow.parameters.parameter-name}} syntax. When users execute the workflow, they can override default values via the execution dialog.
Executing Workflows
- Argo Workflow
- Argo CronWorkflow
Template deployment + parameterized execution
Argo Workflows separate template deployment from workflow execution:1. Deploy Template First (one-time setup, or when workflow logic changes)- Click Deploy Template
- Select deployment options (build new or deploy existing)
- Choose Git references
- Deploy to environment
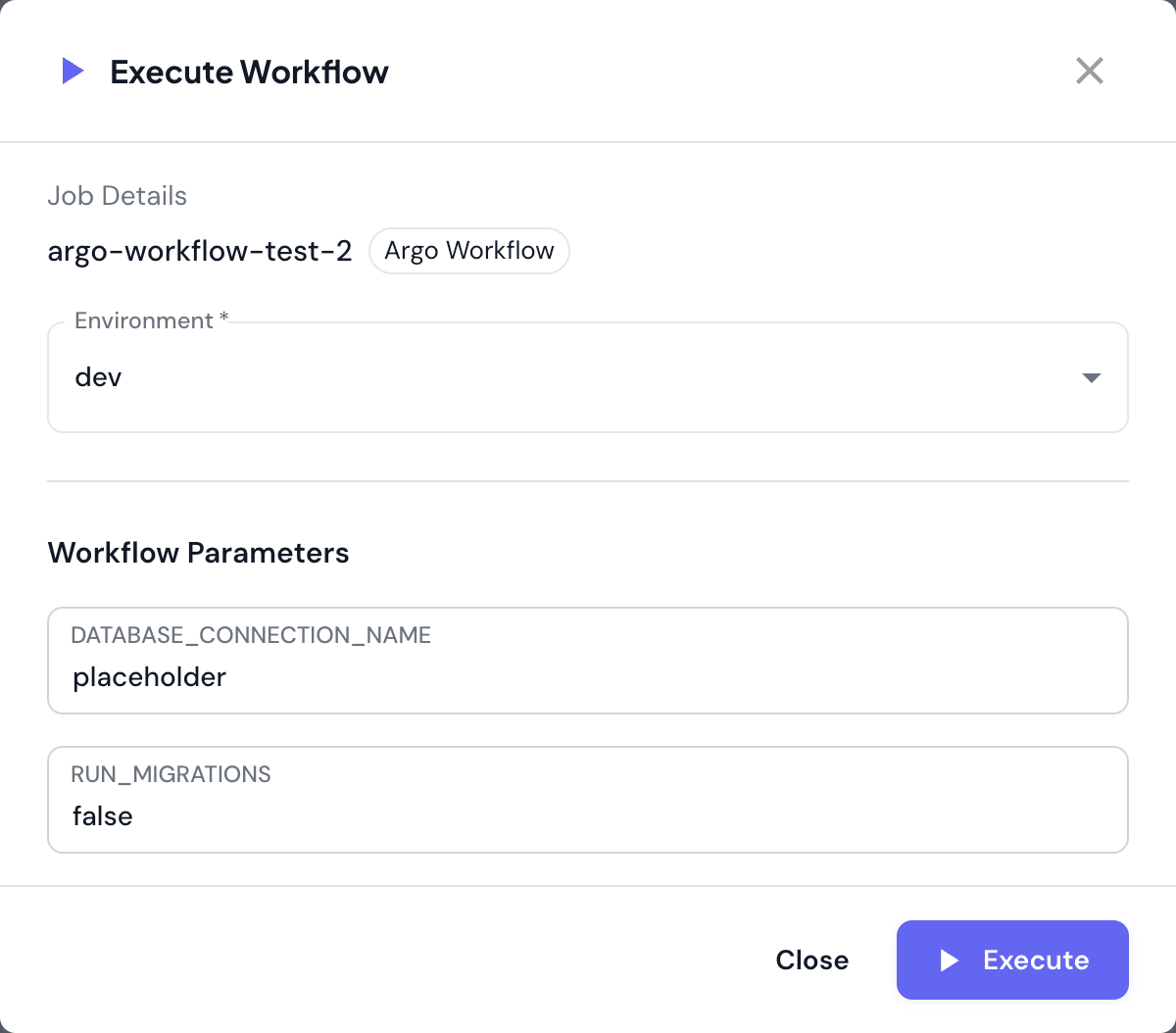
- Click Execute Workflow
- Execution dialog appears with:
- Environment - Select where to execute
- Parameters - Fill in parameter values (if defined)
- Review parameter values
- Click Execute
- Workflow instance created from template
- Parameters injected into workflow
- Workflow orchestrator executes steps in sequence
- Each step creates pods as needed
- Workflow tracks progress through completion
Monitoring Workflows
Executions Tab
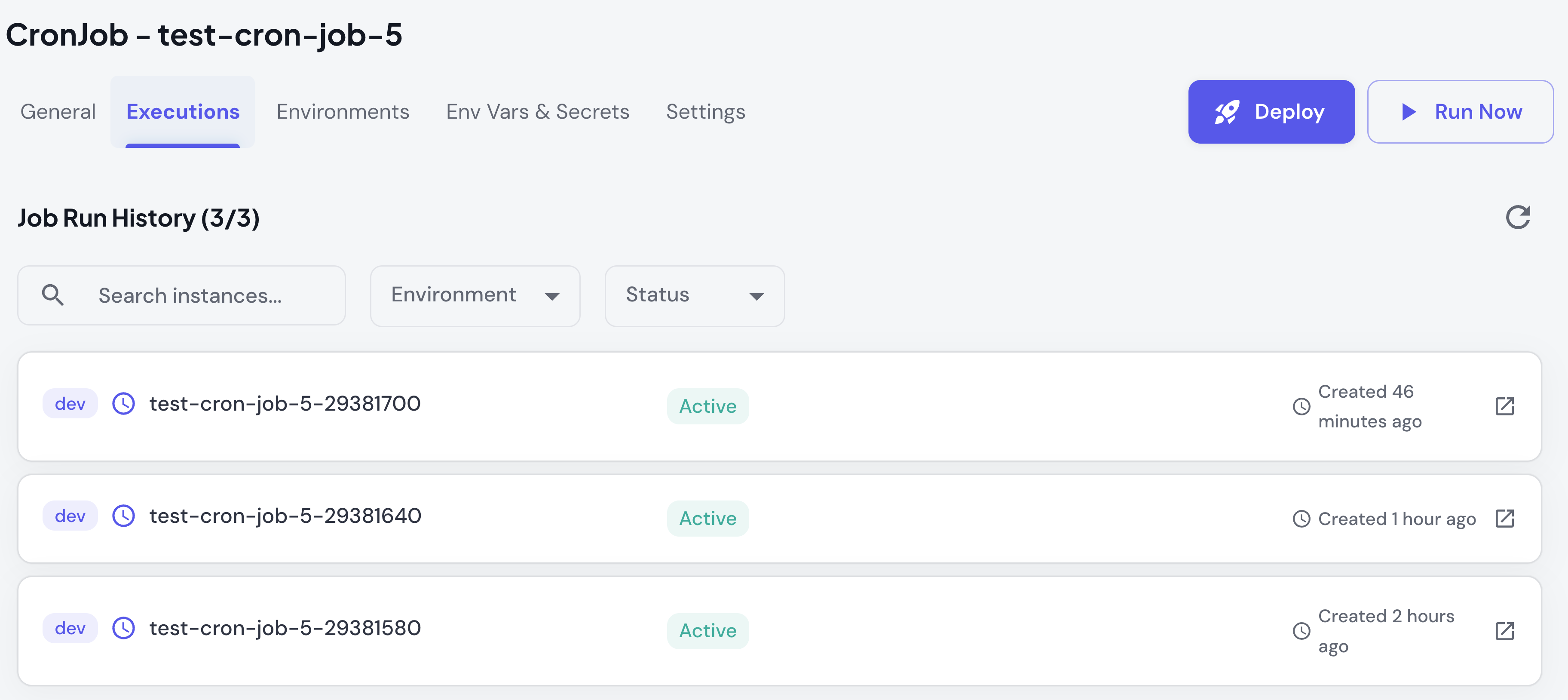
- List of all workflow instances
- Status (Pending/Running/Succeeded/Failed)
- Start time, completion time, duration
- Environment where workflow ran
Workflow Details
Execution details show: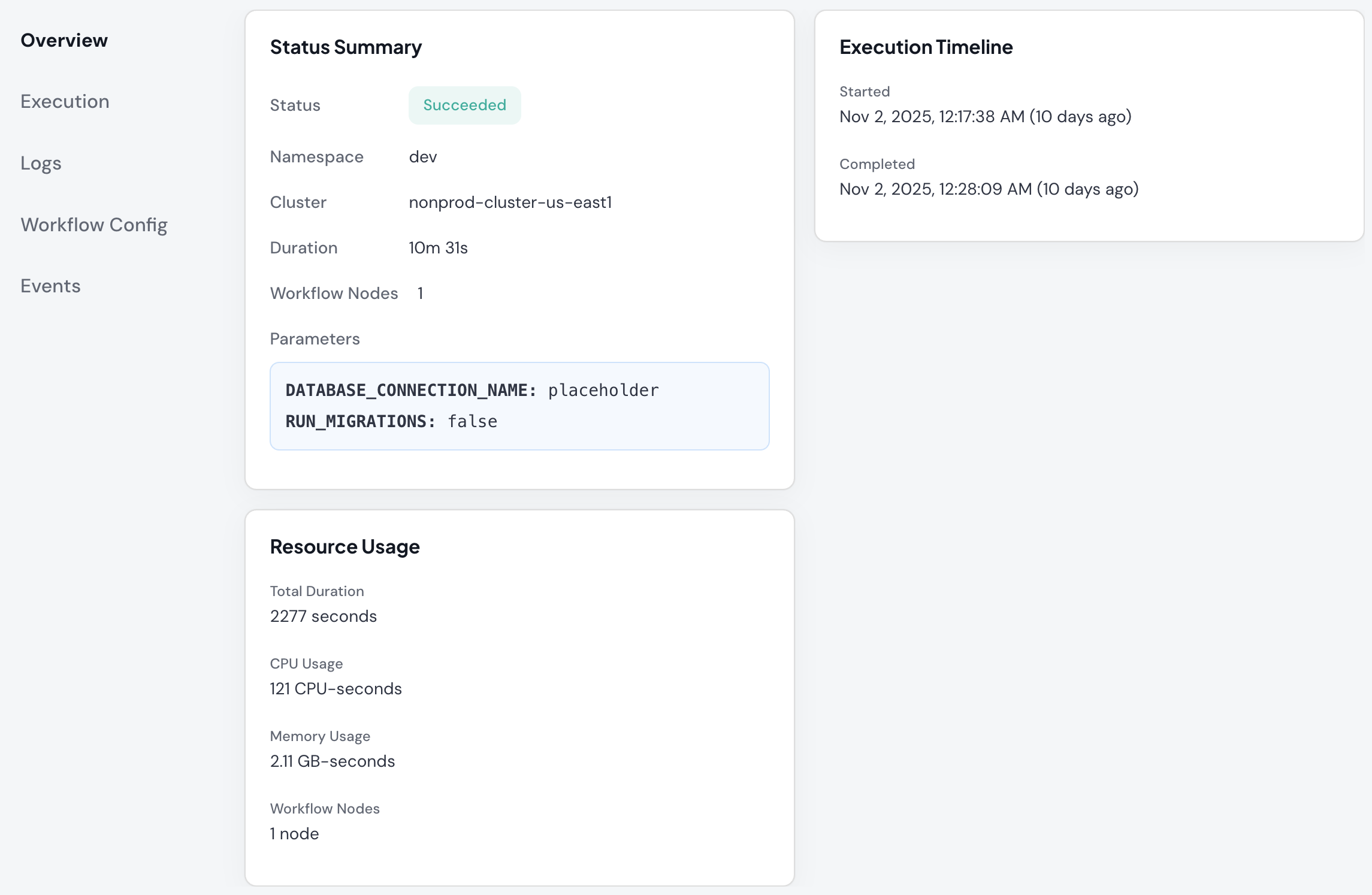
- Overall workflow status
- Total nodes (steps) in workflow
- Completed nodes
- Current executing node
- Failed nodes (if any)
- Visual representation of workflow steps
- Individual step status
- Step dependencies and execution order
- Time spent per step
- Workflow template used
- Parameters provided
- Service account
- Execution limits
- View individual step logs
- Inspect step containers
- Access Argo UI for detailed visualization
Argo UI Integration
For advanced visualization, access the Argo Workflows UI:- Click on a workflow execution
- Click View in Argo UI link
- Opens Argo Workflows dashboard
- Graphical workflow visualization
- DAG (Directed Acyclic Graph) view
- Step-by-step execution timeline
- Artifact browser
- Advanced debugging tools
Viewing Logs
Access Step Logs:- Click on a workflow execution
- Select specific step/container
- Click View Logs
- See logs for that step
Advanced Configuration
Advanced Argo Workflow configuration options using WorkflowTemplate YAML.Workflow Parameters
Workflow Parameters
Define parameters that can be passed at execution time.In WorkflowTemplate:Use in templates:Override at execution via the Skyhook UI when you click “Execute Workflow” - you’ll be prompted to provide values for each parameter.
Retry Strategies
Retry Strategies
Configure automatic retry behavior for failed steps.Exponential Backoff (Recommended):Fixed Delay:Immediate Retry:
Lifecycle Management (TTL)
Lifecycle Management (TTL)
Automatically clean up completed workflows.Clean up all workflows after 1 hour:Different TTL for success vs failure:Recommended TTL values:
- Development: 1-6 hours
- Staging: 6-24 hours
- Production: 24-72 hours (keep longer for audit)
Pod Garbage Collection
Pod Garbage Collection
Control when workflow pods are deleted.Delete pods when workflow completes:Delete pods only on success:Delete each pod when it completes:Never delete pods automatically:
Resource Limits
Resource Limits
Configure CPU and memory for workflow steps.Per-template resources:Template defaults (apply to all steps):GPU resources:
Execution Limits
Execution Limits
Set time limits for workflow execution.Active deadline (workflow timeout):Per-step timeout:Recommended limits:
- API calls: 5-15 minutes
- Data processing: 30-60 minutes
- ML training: 2-6 hours
- ETL pipelines: 2-12 hours
Multi-Step Workflows (Steps)
Multi-Step Workflows (Steps)
DAG Workflows (Parallel)
DAG Workflows (Parallel)
Environment Variables
Environment Variables
Configure environment variables for workflow steps.Static env vars:From parameters:From secrets:From ConfigMaps:
Node Selection & Affinity
Node Selection & Affinity
Control where workflow pods run.Node selector:Tolerations:Affinity: